一:XML&语法
1.介绍XML是extensible markup language简称,跟html一样也是一种标记语言,不过他是可拓展的。
相较于HTML,xml的标签是可以由用户自己定义的,而html则是固定的标签。
而我们通过web服务器上的路径,来访温web上的资源,所以为了路径的灵活设置我们需要使用xml进行配置。即通过使用xml配置路径,执行不同的资源(servlet)。
例:常见的配置文件。
作为一种语言,肯定有对应的语法(约束) ,同时XML还需要解析器来解析。而XML所用到的约束为(DTD或者是schema),解析我们采用dom4j进行解析。
2.语法
语法:格式如上图.xml
CDATA区 :当XML文档结构所引用符号过多而需要大量的使用转义字符时,就可以使用CDATA段就会好一些。具体形式如下:(包含两个[]以及<>)
<! [CDATA[
任意内容
]] >二:XML约束(Schema)
1.DTD语法(了解)
dtd(Document Type Definition)顾名思义 元素类型的定义,是个文档类型.dtd用来约束xml,规定xml文档元素的名称及顺序和属性。通常都是框架提供dtd
如若使用DTD约束,则必须包括DOCTYPE 格式
1.若自己编写,在xml文档内容嵌入DTD,只对当前xml有效。
2.外部DTD
(1)DTD在本地,则一般为公司内部引用
使用 SYSYEM “文件名”
(2)DTD在公共网络,一般有框架提供
使用 PUBLIC “。。。”
2.Schema约束
(1)Schema是一种新的代替DTD的约束,本身也是xml文档,扩展名是xsd,功能强大,数据类型完善。
一般也是由框架提供,要求是通过schema来编写xml文档。
案例文档中同一个“命名空间”通过xsd:schema或者
2)实际开发中,命名空间由框架提供的帮助文档获得
这里我们提到了命名空间,命名空间是用来处理元素和属性的名称冲突问题的,与Java包是同一用途。
(3)声明命名空间
三:dom4j解析
当数据存到xml文档中后,我们就希望能够通过程序来获得xml中的内容,如果我们使用IO流是可以完成获取的,不过开发中为避免繁琐,提供了解析方式,提交了对应的解析器,方便开发人员操作xml。
1,解析方式和解析器
常用的解析方式有三种:
(1)DOM:解析器把整个xml装在进内存,解析成一个Document对象
虽然他们是元素之间保留了结构的关系(对象接方法)可以进行增删改成操作,但文档过大易出现内存溢出
(2)SAX(了解):速度快,有效,逐行扫描,边扫描边解析,每执行一行,触发对应事件。但它只能读。
(3)PULL(了解):Android内置的xml解析方式,类似SAX。
解析器:繁琐的API,一般提供易于操作的解析开发包
解析开发包:
JAXP:sun公司提供的支持DOM和SAX的开发包
JDOM:dom4j的好兄弟
jsoup:一种特定处理HTML的解析开发包
dom4j:比较常用的解析开发包,hibernate底层采用。
2.(重点)DOM解析原理及结构模型
xml DOM 和 HTML DOM类似,XML DOM 是将整个XML文档加载进内存,生成一颗DOM树,并且获得一个Document对象 ,通过Document对象就可以对DOM进行操作。
四:dom4j解析,API使用说明
使用dom4j必须导入jar包。
dom4j 必须使用核心类SaxReader来获取加载xml文档的Document对象,通过Document对象来获取文档的根元素,然后逐个进行操作,常用的API如下:
1.SaxReader对象
// 1.获取解析器
SAXReader saxReader = new SAXReader();
read方法(。。。)加载执行的xml文档。
// 2.获得document文档对象
saxReader.read(“src/cn/itheima/xml/schema/web.xml”);返回值是一个Document 对象.
//3 获取根元素
doc.getRootElement(); 返回值是一个Element 对象
rootElement.attributeValue(“version”)获取根元素的属性值.
//4 获取根元素下的子元素
rootElement.elements(); 返回值是一个集合list<>
List
//5.使用for循环遍历,一节条件判断,拿取到元素内部的名称和属性。
if (“Name”.equals(element.getName())) 先找到要找到的元素
获取servlet-name元素Element servletName = element.element(“servlet-name”);
获取servlet-class元素 Element servletClass = element.element(“servlet-class”);
获取内容文档的信息,servletName.getText()
五:反射&模拟浏览器路径
在java se 基础中已经学习了反射,反射是对于任何一个类,都能够知道他的所有属性和方法,任何一个对象,都能调用它的属性和方法。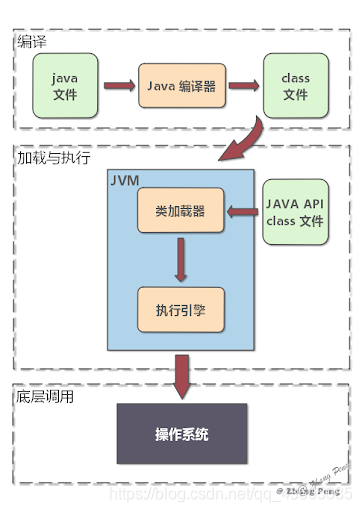
(1)class对象
class对象,是对class字节码文件的描述对象。
获取class对象
一般是Class.forName(…)
已经对象 obj.getClass()
常用的创造实例:newInstance()
(2)Constructor对象 顾名思义构造器和构造方法,构造函数
Constructor getConstructor 可变参数用于确定参数列表
常用的创造实例:newInstance(Object 。。。initargs)
(3)Method对象
Method getMethod(String name,Class。。。parameterTypes)通过方法name获得方法
通常反射是与dom4j解析器结合 用来实现类,以及通过实例newInstance()来执行对象的方法
前面代码便可以加上
模拟浏览器路径
其实质就是servlet的执行过程。name是中间的连接,建立起urlPattern与servletClass之间的联系(通过map中的键值对来实现)

