数据库与缓存
重点学习内容
- 事务隔离级别
- 索引
- Mysql三范式
- 主从复制
- SQL语句的优化
- 缓存策略
- 缓存穿透、击穿和雪崩
- Redis淘汰策略
- Redis持久化
一、关系型数据库(Mysql为例)
1.1 事务的四大特性
- 原子性(Atomicity):事务中所有操作是不可再分割的原子单位。事务中所有操作要么全部执行成功,要么全部执行失败。
- 一致性(Consistency):事务执行后,数据库状态与其它业务规则保持一致。如转账业务,无论事务执行成功与否,参与转账的两个账号余额之和应该是不变的。
- 隔离性(Isolation):隔离性是指在并发操作中,不同事务之间应该隔离开来,使每个并发中的事务不会相互干扰。
- 持久性(Durability):一旦事务提交成功,事务中所有的数据操作都必须被持久化到数据库中,即使提交事务后,数据库马上崩溃,在数据库重启时,也必须能保证通过某种机制redo log恢复数据。
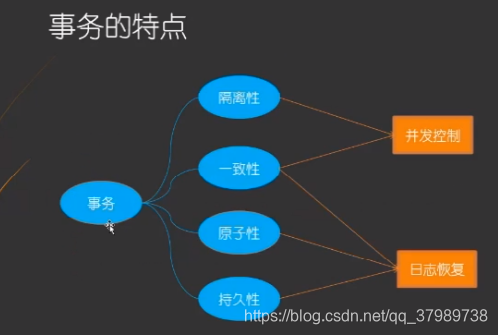
总结:原子性和持久性是通过日志恢复实现,隔离性是通过并发控制(锁)来实现的,而原子性、隔离性、持久性巩固实现一致性。
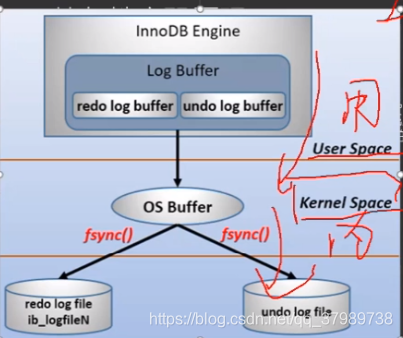
1.1.1 undo log
原子性的实现原理,undo log存储的是数据库的备份数据,通过此日志可以恢复到事务开始的状态(回滚的实现)。
所以它存的就是相反的sql语句,例如插入一条数据,undo log里面就是存的删除语句(因为执行删除才能恢复到原样)。
1.1.2 redo log
持久性的实现原理,redo log存储的是新数据的备份,因为在提交前将redo log持久化,不需要数据进行持久化。
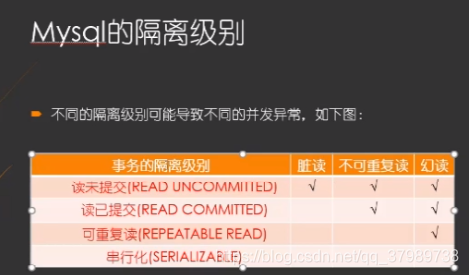
1.2 事务隔离级别
然而完全的隔离性会导致并发的性能很低,事务隔离级别从低到高分别是:
读未提交Read uncommitted: 读写锁均在操作完成后立即释放。
读已提交Read committed: 防止脏读。读锁在读完成后立即释放,写锁持续到事务结束释放。Oracle和sql server的默认隔离等级。
可重复读Repeatable read: (Mysql默认)防止脏读、不可重复读。读写锁均持续到事务结束释放。
串行化Serializable: **防止脏读、不可重复读和幻读。不再锁定行,而是锁定表。直接将表操作串行**。
解释几个概念:
- 脏读(查找):读到其他事务未提交的数据,拿到不该拿的东西
- 不可重复读(修改、删除):同一事务对同一数据前后读取结果不一致,比如在其他事物提交前后进行读取。
- 幻读(插入):像是产生幻觉,事务A对表操作时,事务B添加了新的记录,都能受到B的操作影响了,比如A进行插入时ID与B中刚插入重复,失败。
隔离性实现原理:锁
InnoDB的锁机制:共享锁(读锁)+排它锁(写锁,更新操作默认),既支持表锁也支持行锁

1.3 Mysql常见引擎
引擎是对于数据库的表结构来说的。
1.3.1 InnoDB(支持事务)
支持事务、外键,支持表级锁和行级锁。如果表中既无主键也无索引,将自动创建一个隐藏主键列。适合执行大量的delete和update,适合大尺寸数据库。
InnoDB索引实现(聚集) ,表数据文件本身就是按B+Tree组织的一个索引结构文件,是聚集索引(叶节点包含了完整的数据记录,不用再二次访问)。

常问的面试题:
①为什么InnoDB表必须有主键,并且推荐使用整型的自增主键?
- 因为整型的存储比字段类型要小,而且应为是InnoDB存储引擎使用的是B+Tree数据结构,在进行查询数据是需要对每个元素进行比较,而整型的对比效率是高于其他数据结构的,字符串等
- 而且由于自增的主键而言,B+树是有序的,插入数据也非常方便,范围查找高效
- Mysql是通过B+树组织这些索引的,如果不设定主键Mysql也会默认生成主键比如rowid等;
②为什么非主键索引结构叶子节点存储的是主键值而不是数据?(保障数据一致性、用时间换空间)
INNODB文件和数据文件是聚集的,每个INNODB表可分为两个文件:.frm(表结构),.ibd(表索引和数据),主键索引叶子节点存储的是主键(key)和数据(value),非主键索引的叶子节点存储的是索引的数据 + 主键(value,比如15),这样得到主键的值之后再到主键索引树去搜索一遍,这个过程也成为回表。
1.3.2 MyIsam(不支持事务)
MyISAM索引和数据文件是分离的(非聚集),mysql的数据文件是存储在data目录下的,data下每个文件夹存储的就是每个数据库的文件,一个MyISAM表可分为三个文件:.frm(表结构),.MYI(表索引),.MYD(表数据);
每个叶子节点存储的都是数据的磁盘指针
总结:不支持事务、外键,仅支持表级锁。允许无索引无主键表的存在。数据是可被压缩的,存储空间较小。适合执行大量的select和insert。
1.3.2 Memory
数据存放在内存,访问速度极快,默认使用hash索引。适合需要频繁使用的少量、可允许丢失的临时数据。
1.4 常用数据库优化方式
选取最适用的字段属性:字段应设置得尽可能小;尽量把字段设置为NOT NULL,这样数据库无需去比较NULL;尽可能使用ENUM代替文本类型。
使用连接(join)代替子查询:join不会在内存中创建临时表,所以效率更高。
在有索引的字段尽量不使用函数操作
字符型字段模糊匹配时可使用以下技巧:

正确使用索引
分区分表:对于数据量极大的表,应分区分表存储(垂直分表、水平分表)
1.5 索引
1.5.1 索引种类
普通索引,index:对关键字没有要求。
唯一索引,unique index:要求关键字不能重复。同时增加唯一约束。
主键索引,primary key:要求关键字不能重复,也不能为NULL。同时增加主键约束。
全文索引,fulltext key:关键字的来源不是所有字段的数据,而是从字段中提取的特别关键词。
主键索引不能为空值,唯一索引允许空值;主键索引在一张表内只能创建一个,唯一索引可以创建多个。主键索引肯定是唯一索引,但唯一索引不一定是主键索引。
1.5.2 索引使用原则
列独立:有字段参与的表达中,字段独立在一侧(如where num+1 = 20无法使用索引)
左原则:like模糊匹配不得以通配符开头(如field like ‘%keywork’需要使用全文索引)
OR:使用or时,左右两端都需要能够使用索引。
有时mysql会智能选择是否使用索引。
1.5.3 B+树
- 红黑树缺点
如果采用普通的树,或者红黑树来存储索引的话,树的高度h就会很高,每次查找都会进行一次I/O操作访问磁盘,影响性能。
故就需要树横向发展,“平铺开来”,于是考虑B树
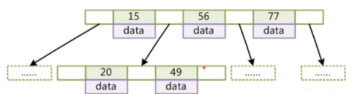
B树
①叶节点具有相同的深度,叶节点的指针为空。
②所有索引元素不重复,也就不是冗余的。
③节点中的数据索引从左到右递增排列。
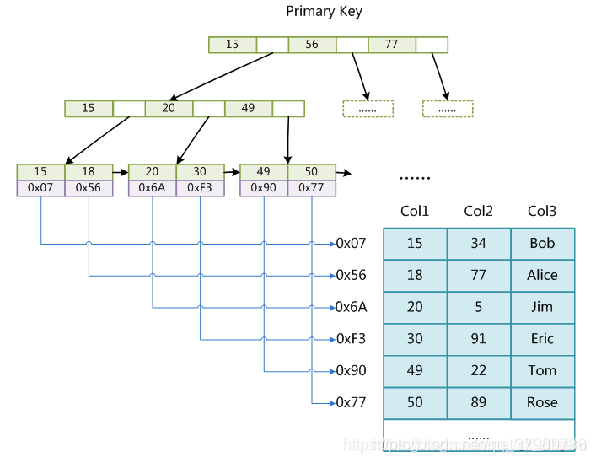
它的存储结构如下图所示,每个节点的索引和数据都存储在一起。
缺点:虽然B树解决了索引量的存储问题,但是进行范围查询时例如where ID > 15时,需要每次进行重新返回根结点查询,性能较低。
B+树
MySQL索引并没有采用B树而是采用B+树,B+树相对于B树具有以下特点:
①非叶子节点不存储data,只存储索引(冗余),可以放更多的索引。
②叶子节点包含所有索引字段,且节点索引依次递增。
③叶子节点用指针连接,提高区间访问的性能。

在Mysql中,索引一般为bigint类型占8个字节,对于索引后面的指针占用6个字节,而Mysql给第一层大节点的限制内存大小为16KB,因此大概可以存储16KB/(6+8)B=1170个索引,同样第二层也可以存储1170个,而对于高度为3的B+树来说,假设第三层的索引和数据占用1KB大小,可以存放16KB/1KB=16个索引(加数据),因此总共可以存储1170 x 1170 x 16 = 21,902,400个数据,2000多万条数据,令人诧异!!
注意:Mysql中极少情况下也可以用Hash表来存储,但像B树一样不适合于范围查询。
1.5.4 聚集与非聚集索引
非聚集索引:叶子节点里,只是指向数据的地址,并非有真正的数据,MyISAM引擎采用
聚集索引:叶子节点的data里放的索引所在行的完整数据字段,不用二次访问。InnoDB引擎采用
每个表只能有1个聚集索引。可以有多个非聚集索引。
- 联合索引
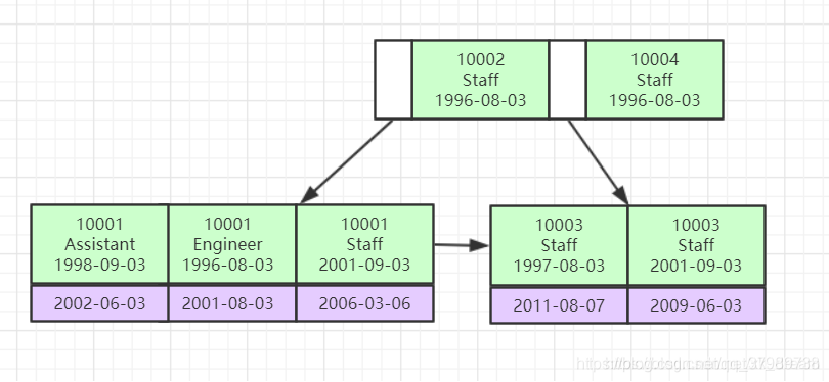
联合索引非叶子节点存储的是联合索引(key)和主键(value),其索引的顺序是按索引常见的顺序排的,先按第一个索引排序,再按第二个索引排序…
对于Hash索引的话,不支持区间范围查询,但是速度的确比B+树要快,B+树的双向链表支持范围查询,但是仅仅简单查询的话,Hash索引还是比B+树索引要快的。
1.6 数据库三范式
1.6.1 1NF
数据库表的每一列都是不可分割的原子数据项,例如不能出现学生字段,数据为“张三 男 18岁”。
1.6.2 2NF
在1NF的基础上,非主键字段完全依赖于主键,不能是联合主键。
1.6.1 3NF
在2NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖)
1.7 主从复制
1.7.1 主从复制的方式

1.7.2 主从复制的作用
- 数据热备
- 多库存储,读写分离
读写分离技术:适用于写多读少的数据库,利用了主从复制的原理,实现了多库存储。
1.7.3 主从复制原理
- 主数据库操作,sql语句写入数据库的同时,写入binlog二进制文件,主要是一些SQL语句(写库,所以是增删改)。
- 主库通过I/O线程发送binlog,写入至从库replay log
- 从库执行SQL线程将replay log,写入至从库的bin log data中。
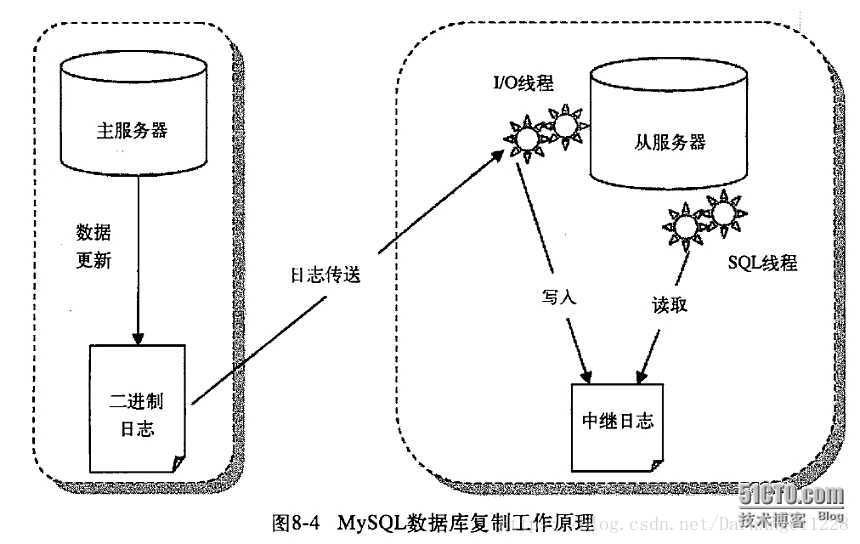
但主从复制也会引发问题,比如脏读,牺牲了数据库的一致性,产生延迟。
1.8 半同步复制
解决主库宕机后数据丢失的问题(bin log没传走):
至少有一个确认从库的relay log接收到bin log后,用户线程才返回success,但会带来更高的延迟。
1.9 Mysql查询缓存
Mysql会缓存sql语句的hash值和查询结果。但有两个弊端:
对表有任何改动都会清空该表的所有缓存。
依靠sql语句的hash值查询缓存结果,两条sql语句必须大小写和空格格式完全相同才可查询到。
二、非关系型数据库(Redis为例)
2.1 缓存
2.1.1 缓存的类型
本地缓存:在进程的内存中实现缓存。优点:本地访问,无远程交互开销。缺点:容量较小
分布式缓存:采用分布式系统管理缓存。
多级缓存:访问频率较高的数据使用本地缓存,其余使用分布式缓存。
2.1.2 常见缓存策略
基于访问时间
基于访问频率
时间与频率兼顾
基于访问模式(针对某些有明确访问特点的数据)
2.1.3 缓存预热、穿透、击穿和雪崩
- 缓存预热:缓存系统启动前,提前将相关缓存数据加载到缓存系统,避免在系统开启时,先查询数据库。
步骤:
- 前置准备:统计数据的访问记录,统计高热点数据;利用LRU删除策略,留存数据建立队列,依次放到文件事件分派器,事件分派器将事件分发给事件处理器。
- 准备工作:将热点数据分级,优先加载级别较高的数据
- 实施:数据预热(使用脚本)
- 缓存雪崩:较短时间内,大量热点数据集中过期,造成一瞬间DB压力陡增。
解决方法:
- 数据过期时间随机设置,防止大量数据同时过期
- 热点数据均匀分布在不同数据库
- 设置热点数据永不过期
- 加锁限流,只允许一个线程查询和写缓存,慎用。
- 缓存击穿:缓存中的某个热点数据到期后,大量请求同时发向DB(缓存没有DB有)。
解决方法:
设置热点数据永不过期
加互斥锁(分布式锁)SETNX,是「SET if Not eXists」的缩写,也就是只有不存在的时候才设置,可以利用它来实现锁的效果。
public String get(key) {
String value = redis.get(key);
if (value == null) { //代表缓存值过期
//设置3min的超时,防止del操作失败的时候,下次缓存过期一直不能load db
if (redis.setnx(key_mutex, 1, 3 * 60) == 1) { //代表设置成功
value = db.get(key);
redis.set(key, value, expire_secs);
redis.del(key_mutex);
} else { //这个时候代表同时候的其他线程已经load db并回设到缓存了,这时候重试获取缓存值即可
sleep(50);
get(key); //重试
}
} else {
return value;
}
}
- 缓存穿透:大量访问一个不存在的key(缓存和DB都不存在),请求会大量穿透到DB,例如
解决方法:
- 访问key未查询到值,也将空值null写入缓存并返回,赋予较短的过期时间,但会导致一段时间不一致性。
- 采用过滤器,维护一个集合保存所有可能被访问到的key,不存在的key直接过滤掉。命中率可以忽略
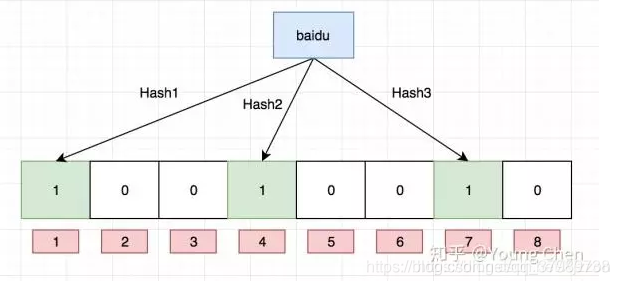
例如布隆过滤器:
对一个key进行k个hash算法获取到k个值的位置,设定为1,如果查询的key的k个位置全为1则说明有,但是会出现误判。
2.2 Redis
2.2.1 Redis的五种数据结构
数据结构都是说的是Redis中的value的数据结构,Redis本身就是一个Map,只不过他的key永远都是String类型的。

- String:将Json数据序列化为字符串,塞进 Redis 来缓存。
(1)批量键值对mget和mset:可以批量对多个字符串进行读写,节省网络耗时开销
(2)过期和 set 命令扩展expire或者是setex:可以对 key 设置过期时间,到点自动删除,这个功能常用来控制缓存的失效时间。
(3)value 值是一个整数,还可以对它进行自增操作。自增是有范围的,它的范围是 signed long 的最大最小值
- List:底层quickList,一种由zipList构成的双向链表(即每一个元素都是一个zipList),类似于LinkedList
(1)常常用作消息队列使用:需要延后处理的任务,序列化成list,然后另一个线程就轮询这个list,拿取。
(2)一般使用 rpop,rpush和lpop,lpush来实现 一边进一边出 的栈和 一边进另一边出 的队列
- Hash:底层使用的是数组 + 链表,类似于HashMap,无序,拉链法解决hash碰撞。
(1)key依然是字符串,value是个hash表
(2)Hash可以对用户字段进行单独存储,例如hset userId username “张三”,就可以实现部分数据获取,避免整个获取浪费网络流量。
缺点也是显而易见,字段单独存储,存储消耗很高。
Set:底层hashtable,无序的,适合于查询操作。
它的内部实现相当于一个特殊的hash表,字典中所有的 value 都是一个值NULL。
Zset:底层使用跳表或zipList,有序的且唯一,一方面它是一个 set,保证了内部 value 的唯一性,另一方面它可以给每个 value 赋予一个 score,代表这个 value 的排序权重,可以用来排序。
List、Set、ZSet的比较

2.2.2 Redis的单线程和高性能
1. Redis 单线程为什么还能这么快?
●因为它所有的数据都在内存中,所有的运算都是内存级别的运算
●而且单线程避免了多线程的切换性能损耗问题。正因为 Redis 是单线程,所以要小心使用 Redis 指令,对于那些耗时的指令(比如keys),一定要谨慎使用,一不小心就可能会导致 Redis 卡顿。
2. Redis 单线程如何处理那么多的并发客户端连接?
Redis的IO多路复用:redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,依次放到文件事件分派器,事件分派器将事件分发给事件处理器。
Nginx也是采用IO多路复用原理解决C10K问题

2.2.2 Redis淘汰策略
- 检查volatile易失数据(有时效的,有expires的)
- volatile-lru:淘汰掉设置了过期时间的最近里最少使用数据
- volatile-lfu:淘汰掉设置了过期时间的一段时间里最少使用数据
- volatile-ttl:淘汰掉设置了过期时间的将要过期的数据
- volatile-random:随机淘汰掉设置了过期时间的数据
- 检查全库的数据(所有的数据集)
- allkeys-lru:从全部数据中淘汰掉最近里最少使用数据
- allkeys-lfu:从全部数据中淘汰掉一段时间里最少使用数据
- allkeys-random:从全部数据中随机淘汰数据
- 放弃数据驱逐
- no-enviction(驱逐):不淘汰数据,对写入报错(OOM)
2.2.3 数据库与缓存一致性解决方案
先删除缓存,在更新数据库。更新数据库的操作与缓存查询数据库的操作在同一队列。
2.2.4 持久化
RDB机制 == 内存数据库完整备份(全部数据)
AOF机制 == 内存数据库日志备份(每一条指令)
2.2.4.1 RDB快照
Save操作。默认情况下, Redis 将内存数据库快照保存在名字为 dump.rdb 的二进制文件中(并且启动时加载文件),并且可以设置时间间隔和改动数。
RDB优点:
(1)RDB 是一个非常紧凑(compact)的文件,它保存了 Redis 在某个时间点上的数据集。
(2)RDB 可以最大化 Redis 的性能,保存 RDB 文件时唯一要做的就是 fork 出一个子进程,然后这个子进程就会处理接下来的所有保存工作,父进程无须执行任何磁盘 I/O 操作。
(3)RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
RDB 的缺点:
(1)如果需要尽量避免在服务器故障时丢失数据,那么 RDB 不适合,因为RDB 文件需要保存整个数据集的状态, 所以它可能会至少 5 分钟才保存一次 RDB 文件。 在这种情况下, 一旦发生故障宕机, 你就可能会丢失好几分钟的数据。
(2)每次保存 RDB 的时候,Redis 都要 fork() 出一个子进程,并由子进程来进行实际的持久化工作。 在数据集比较庞大时, fork() 可能会非常耗时。
2.2.4.2 AOF日志(主流)
Redis 因为RDB而造成故障停机, 那么服务器将丢失最近写入、且仍未保存到快照中的那些数据。那么Redis 采用了实时性的启动优先级高的持久化方式: AOF 持久化,将修改的每一条指令记录进文件,避免了save才去保存的非实时性且数据集大的特点。
每当 Redis 执行一个改变数据集的命令时(比如 SET), 这个命令就会被追加到AOF写命令刷新缓存区里,然后再将命令同步到.aof文件中。重启时, 程序就可以通过重新执行 AOF 文件中的命令来达到重建数据集的目的。
AOF写数据的三种策略(appendfsync)
- appendfsync always
- appendfsync everysec
- appendfsync no
always 每写入一条数据,立即将这个数据对应给的写日志fsync到磁盘上去,性能会变得很差,但是可以确保说每一条数据都不会丢失
everysec 每秒将os cache中的数据fsync到磁盘,这个最常用,生产环境下一般都使用这种策略,性能很高。
no 仅仅负责将数据写到os cache就可以了,不进行fsync等待操作系统对这些数据写入磁盘,这种策略,会让我们的数据不可控,因为无法预知操作系统什么时候会把数据刷到磁盘。
- 重写
很多数据可能会自动过期,也有可能会被用户删除,但是这些操作都会被AOF文件记录下来会出现AOF记录的命令体积超出保存数据集状态的情况,而且重建数据集根本不需要执行所有下,会进行一个重写(rewrite)操作,确保文件不会太大。
重写的过程:
(1)fork一个子进程,子进程基于当前内存中的数据往一个新的临时AOF文件中写入日志;主进程如果接收到client的写操作,在内存中写入日志,同时新的日志也继续写入旧的AOF文件;
(2)子进程完成新的日志文件之后,主进程将内存中的新日志再次追加到新的AOF文件中;用新的日志文件替换旧的日志文件。
AOF 的优点:
AOF 的默认策略为每秒钟 fsync 一次,在这种配置下,Redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据( fsync 会在后台线程执行,所以主线程可以继续努力地处理命令请求),它也是轻量级的。
AOF 的缺点:
对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积,从而恢复速度就会很慢。
2.2.5 哨兵模式
采用哨兵进程监控主redis服务器和从redis服务器。当主服务器宕机,哨兵通知其他从服务器切换为主机。(哨兵之间也会互相监控)
哨兵机制:
监控:同步各个节点的状态信息:先检查各个的哨兵状态哨兵,看是否在线;获取master的状态,最后获取所以slave状态。
工作顺序:
(1)info知道状况,建立cmd连接
(2)哨兵端:保存所有的哨兵状态;Master端:保存Redis实例(即主从缓存服务器)
(3)连接每个slave,使得哨兵信息完整
(4)其它哨兵再与主机建立cmd连接
(5)哨兵间互发ping命令,确认状况
通知:当被监控的服务器出现问题时,向其他哨兵发送通知
哨兵会向主从服务器发送hello指令,以确保其状态,然后在哨兵之间网络进行消息互通。
自动故障转移:断开master与slave,选一个当master(投票),告知连接新的master,告知客户端新的地址。
若hello无响应,将master的标志位置为主观down,则其他哨兵也去“问候”主机,确认挂了,则设置为客观down。
哨兵之间竞选(主要根据竞选次数与投票接受顺序),得到投票结果,则执行哨兵选取新的master,其他slave再切换主机。
2.2.6 Redis数据过期策略
定时删除:定时遍历redis,查看有无过期数据,删除之。
惰性删除:数据被get即被访问时时,再检查其是否过期。
综合(定期删除 ):定时随机抽取某个expires[*]中的数据检查有无过期删除,同时使用惰性删除。