OS + 计网 + 数据库Mysql + 缓存redis
一、OS
1. 进程与线程的区别
- 进程是资源CPU分配的基本单位,而线程则是调度的基本单位,可以看做是进程中的一条执行流程。
- 进程拥有完整的资源平台,而线程则只独享必不可少的资源,例如寄存器、栈。所以线程能减少并发执行的时间、空间开销。
- 进程切换要涉及到用户态与内核态之间的切换,还要管理资源信息、内存空间信息(页面的切换),而线程则不需要。
- 进程的创建与撤销开销比线程大很多(管理内存空间、I/O设备)
2. 作业调度算法
作业调度算法主要分为两类:非抢占式调度 和 抢占式调度。
非抢占式:一个线程被调度运行完后,才会运行下一个线程,期间一直被阻塞。
抢占式调度:一个线程执行过程中,时间片用完发生中断调度下一个线程运行。
先来先服务:最基本的算法,非抢占式的,有利于长作业。
短作业优先:顾名思义,利于短作业,长作业可能会长期等待。
高响应比优先:兼顾了长短作业,要求服务时间少 + 等待时间长(分别对应短作业和长作业)会优先执行。
时间片轮转:每个线程分配相同时间片,执行完后调度下一个。
优先级调度:顾名思义,选择最高的优先级进行调度,一般是动态优先级,等待时间长的线程优先级就增加,防止永远等待。
多级反馈队列调度算法:基于最高优先级 + 时间片轮转算法
(1)维护多个优先级队列:优先级越高,时间越短
(2)调度按照优先级调度,如果时间片结束未执行完线程,则加入后面队列的尾部,等待调度,以此类推
兼顾了长短作业,有较好的响应时间。
3. 进程间通信
(1)等价于不同进程下的线程通信,同进程下线程直接通信,更多关注锁(例如信号量)实现多线程共享资源的同步互斥问题。
(2)进程内存地址都是独立的,只有内核空间是进程共享的,所以进程间通信、数据传输都需要经过内核态。
- 管道:管道是一种半双工的,数据只能单向流动的(固定大小字节流)尾部写,头部读。
主要分为两类:管道(匿名管道)、命名管道,区别就是:管道用完就销毁,并且只能具有父子关系的进程调用,而命名管道一直存在,且允许非父子关系的进程通信。
特点:效率低,不适应频繁交换。
- 消息队列:保存在
内核中的消息链表,它分成了一个个独立的数据块(有类型、大小),这与无格式字节流的管道相区别。
特点:通信不是实时性、会进行数据拷贝,涉及到用户态和内核态的数据拷贝开销。
- 共享内存:用共享内存的方法,解决了消息队列的数据拷贝开销大的问题,不涉及到用户态与内核态的切换。
原理:两个进程拿一块虚拟内存,映射到相同的物理内存(两进程相互独立,其余虚拟内存就算虚拟地址相同都不映射到一块物理内存)
- 信号量:实质就是一个整数型的计数器,P、V原语操作来实现进程间互斥与同步。
一般使用 信号量 + 共享内存 来实现同步通信。
- 信号:
kill通知接受进程已经发生,所以它是一个异步通信;进程也可以发送信号给自己本身。 - Socket套接字:
不同主机上的跨网络的进程通信,通过绑定IP和端口,来实现数据传输。
4. 死锁条件
- 资源进行互斥等待
- 资源不可被抢占
- 保持并等待(阻塞不放弃自己资源)
- 循环等待(相互等待其释放资源)
5. 分段分页、缺页调度
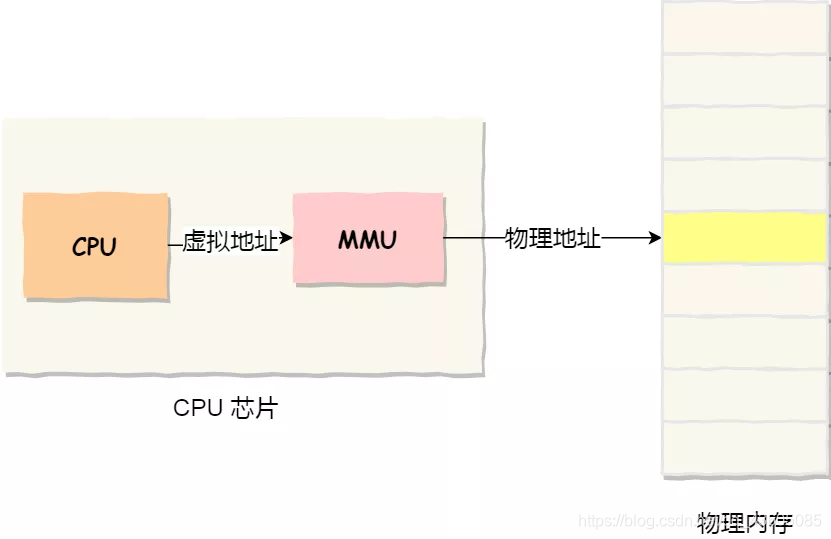
- 虚拟内存
每个进程操作的都是独有的地址空间(虚拟地址),不直接控制访问物理内存。
如何管理?如何映射到物理内存?这就需要分段和分页来映射到物理内存上。
- 分段
分段是内存连续存储,将虚拟内存进行逻辑分段,例如代码段、栈段、数据段、堆段
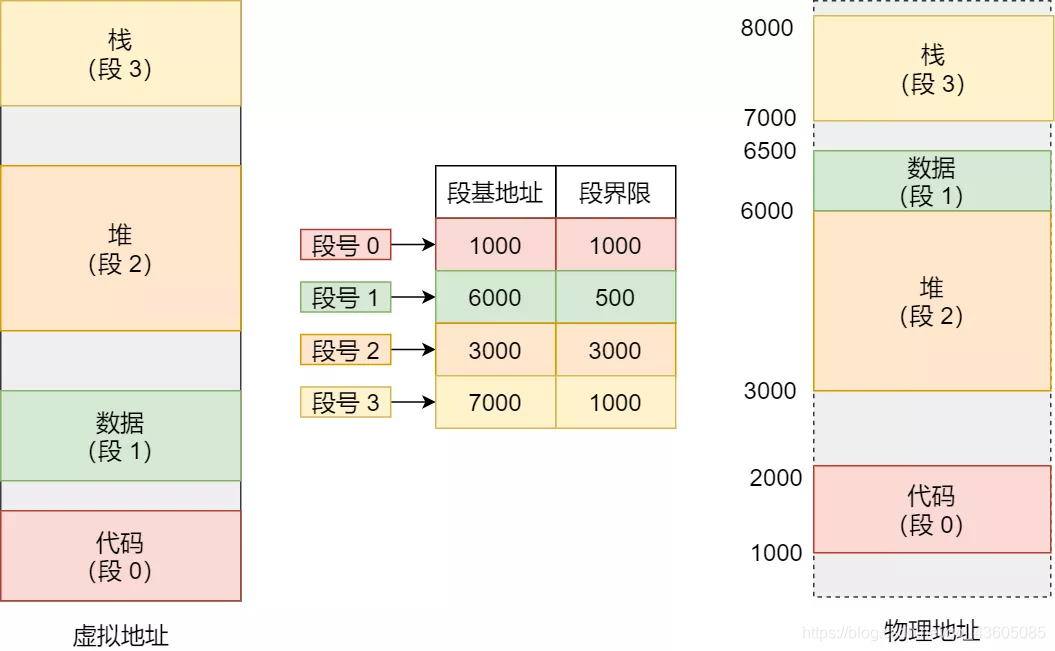
如何映射到物理内存?通过段表:虚拟内存是 段号 + 段内偏移 。通过段号去段表查段的起始地址。
缺点:1. 产生内存碎片化问题,外部碎片大 2. 交换效率低,碎片太多,且段内存大换入换出频繁出现卡顿。
- 分页
分页是把虚拟内存以及物理内存切成一个个固定大小(4KB)的页,同理页表进行映射:页号 + 偏移地址。
当页表中查询不到页号对应的基地址时,会产生缺页中断,进行缺页调度。
分页好处:
(1)释放内存以页为单位释放,所以就不会产生外部碎片化问题,但内部会有碎片。
(2)交换效率高。进程中由于局部性原理,不会一次性申请全部内存,需要时再申请,从磁盘中换入,所以页表就只有很少的页数,交换效率高。
简单分页的话,由于页大小很小,所以个数很多,页表很大,所以引出多级页表来分散。
多级页表:
如果某个一级页表的页表项没有被用到,也就不需要创建这个页表项对应的二级页表了,即可以在需要时才创建二级页表。
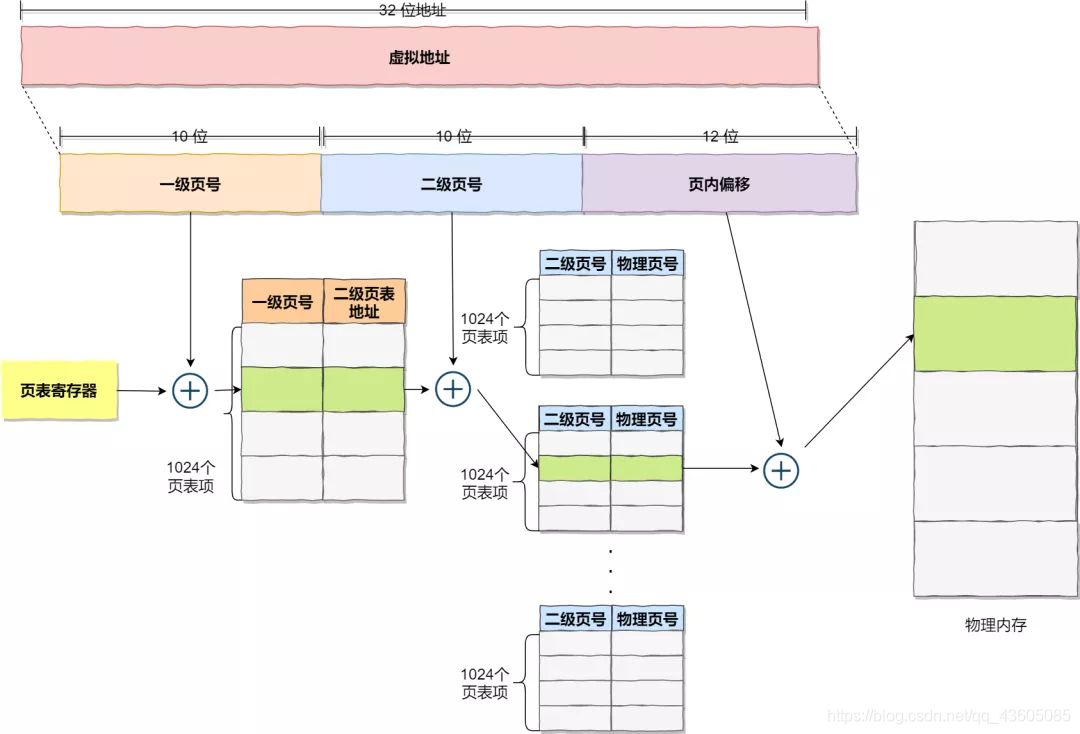
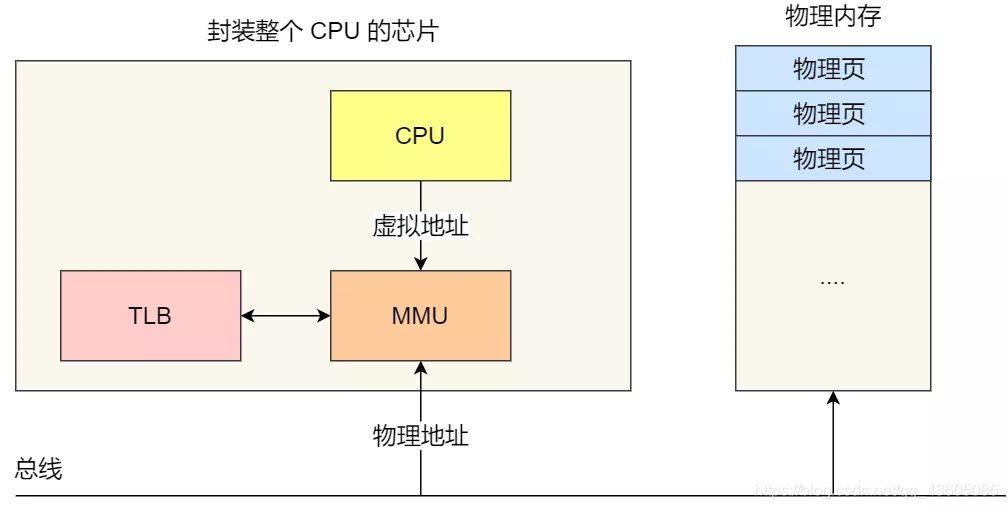
快表(TLB):多级页表多次转换,需要的时间开销比较大,根据程序的局部性,所以就每次把经常访问的那几页放到TLB(页表缓存、块表中)。
即每次查询,就先查TLB,再去页表查。
- 段页式
通常OS,都是段页式一起使用。
- 先将程序化成逻辑上的段
- 再把每个段分成页
地址结构:段号 + 段内页号 + 页内偏移。
- 缺页调度算法
- 先来先出
- 最优置换(理论)
- 最近最少使用(LRU)
- 时钟算法(二次机会改进)
6. 磁盘调度
- 先来先服务
- 最短寻道优先
- 扫描算法
- 循环扫描算法
二、计网
应用层:Http
1. Http常见状态码?常见字段?
- 常见状态码:
除了那些常见200,404,500服务器内部错误。
就是3xx 类状态码表示客户端请求的资源发送了变动,需要客户端用新的 URL 重新发送请求获取资源,也就是重定向。
- 常见字段:
Host:主机地址,客户端发送请求时,用来指定服务器的域名。
Content-Length 字段:服务器在返回数据时,会有 Content-Length 字段,表明本次回应的数据长度。
Connection 字段:Connection 字段最常用于客户端要求服务器使用 TCP 持久连接,以便其他请求复用。
注意:HTTP/1.1 默认连接都是持久连接,但为了兼容老版本的 1.0,扔需要指定为 Keep-Alive。
Content-Type 字段:Content-Type 字段用于服务器回应时,告诉客户端,本次数据是什么格式。
2. Get与Post方式有什么区别?
Get 方法的含义是请求从服务器获取资源,服务器就会返回文章的所有文字及资源。
Post方法的含义恰恰相反,它向 URI 指定的资源提交数据,数据就放在报文的 body 里。(为了数据传输安全)
- 在 HTTP 协议里,所谓的「安全」是指请求方法不会「破坏」服务器上的资源。
- 所谓的「幂等」,意思是多次执行相同的操作,结果都是「相同」的。
GET 方法就是安全且幂等的,因为它是「只读」操作,无论操作多少次,服务器上的数据都是安全的,且每次的结果都是相同的。
POST 因为是「新增或提交数据」的操作,会修改服务器上的资源,所以是不安全的,且多次提交数据就会创建多个资源,所以不是幂等的。
- 对于 get 方式的请求,浏览器会把
header 和 data一并发送出去,服务器响应 200(返回数据) - 对于 post,浏览器先发送 header,服务器响应 100 continue,浏览器再发送 data(确认安全),服务器响应 200 ok(返回数据)。
3. 说一说Http的无状态与长,短连接吧!
- 无状态:浏览器对于事务的处理没有记忆能力。
状态记录的作用的是一个叫做 小甜饼(Cookie) 的机制。它能够让浏览器具有记忆能力。每次会话开始时服务器建立一个会话级别的cookie对象,接下来客户端每次向同一个网站发送请求时,请求头都会带上该 Cookie信息(包含 sessionId ), 然后,服务器读取请求头中的 Cookie 信息,来判断用户信息。
- 长连接、短连接
Http1.0是短连接,每次发出请求,都需要新建一次 TCP 连接(三次握手)。
HTTP/1.1 提出了流水线的长连接的通信方式,未提出断开连接,就保持 TCP 连接状态。这种方式的好处在于减少了 TCP 连接的重复建立和断开所造成的额外开销,减轻了服务器端的负载。
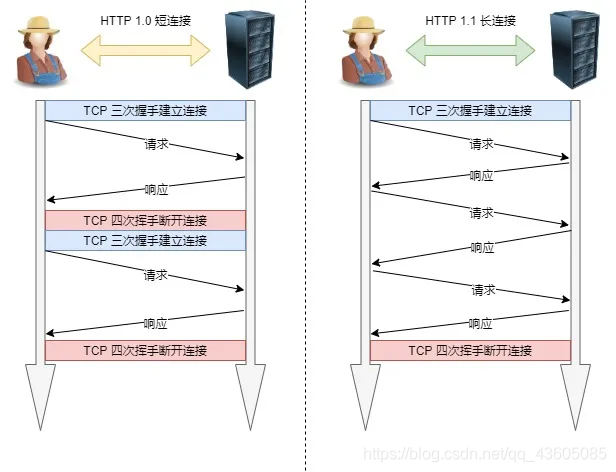
4.能说说Http1.0与1.1与Http2的演变过程及其区别?
- Http1.0 -> Http1.1:
Http1.0的短连接,规定浏览器与服务器只保持短暂的连接,浏览器的每次请求都需要与服务器建立一个TCP连接(一次请求就挥手握手)。Http1.1的长连接,但是为了兼容旧版本,需要显式指明。在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟。采用了流水线的持久连接,即客户端不用等待上一次请求结果返回,就可以发出下一次请求。
Http1.0不支持Host请求头字段,WEB浏览器无法使用主机头名来明确表示要访问服务器上的哪个WEB站点。它认为一个服务器就绑定一个站点。Http1.1增加Host请求头字段后,在一台WEB服务器上可以在同一个IP地址和端口号上使用不同的主机名来创建多个虚拟WEB站点。
Http1.1带宽优化,不再返回额外的对象信息,且提供了Cache缓存等机制的请求头和响应头。
- Http1.1->Http2:
Http1.1头部字段信息没有压缩,信息太大,而body却小的情况,故Http2中进行了头部压缩,提高速度。
Http1.1报文中的信息都是采取了ASCII码,而Http2.0报文中的信息改为二进制格式,称为帧,这种形式对传输速率很高,无需解析报文。
Http2.0基本上都是跑在Https上的,安全性高。
Http2.0采取了多路复用,连接上多个请求,无需每个请求都绑定个连接。
5. 能说说Http与Https的区别吗?
(1)对称加密只使用一个密钥,运算速度快,密钥必须保密,无法做到安全的密钥交换。
(2)非对称加密使用两个密钥:公钥和私钥,公钥可以任意分发而私钥保密,解决了密钥交换问题但速度慢。
- HTTP 连接建立相对简单, TCP 三次握手之后便可进行 HTTP 的报文传输。而 HTTPS 在 TCP 三次握手之后,还需进行 SSL/TLS 的握手过程,才可进入加密报文传输。
- HTTP信息是明文传输,存在安全风险的问题。HTTPS 也就是在 HTTP 与 TCP 层之间增加了 SSL/TLS 安全传输层,使得报文能够加密传输。通过 密钥交换算法 - 签名算法 - 对称加密算法 - 摘要算法 能够解决上面这些问题。
- HTTPS在通信建立前采用非对称加密的方式交换「会话秘钥」,后续全部使用对称加密的「会话秘钥」的方式加密明文数据。
- HTTP 的默认端口是 80,而 HTTPS 的默认端口是 443。
6. Https加密过程
客户端向服务器发起请求(带上随机数1),服务器对客户端进行回应(带上随机数2),并带上自己的SSL证书
客户端会对证书进行校验(内置的受信任的证书发布机构CA,与服务器发来的证书中的颁发者CA比对,用于校验证书是否为合法机构颁发 )
校验无问题后取出公钥,再产生一个随机数,使用三个随机数结合生成对称密钥,用对称密钥来对称加密内容,并用公钥非对称加密对称密钥后,一起发送给服务器。
服务器用私钥解密就能得到对称密钥,两者之后就一直使用这个对称密钥对信息进行加密通信。
传输层:TCP、UDP
1. TCP头部结构
除了源端口和目的端口外,还有最重要的序号、确认号、一些标记位等。
- 序号:seq:每发送一次就加1,用来解决网络包乱序。
- 确认号:ack:下次希望收到的序列号,主要方便发送方下次发送,解决不丢包的问题。
- 标记位:
- ACK:该位为
1时,「确认应答」的字段变为有效,TCP 规定除了最初建立连接时的SYN包之外该位必须设置为1。 - SYC:发送请求通讯,建立连接时,一般来回为1
- ACK:该位为
2. UDP与TCP的区别
- TCP是面向连接的;UDP是无连接,发送前无需连接,但可以用connect指定只与这台主机交互。
连接:有保证可靠性和流量控制的状态信息,有Socket、序列号、窗口大小。
- TCP是一对一的;而UDP可以支持一对一,一对多,多对多通信。
- TCP是面向字节流的,把数据看做一长串字符流;而UDP则是面向报文的。
- TCP是可靠的,数据保证无差错,不丢失,不重复;而UDP是不保证可靠性的。
- TCP拥有拥塞控制以及流量控制机制;而UDP则是无论如何拥堵依旧保持一样的发送速率。
- TCP头部较长,开销大,且长度可变;而UDP头部较小固定8字节,开销小。
3. 为什么是三次握手,不是两次?四次?
- 握手目的:
建立TCP连接,即初始化Socket、序列号、滑动窗口的大小。
- 三次握手过程:
(1)开始client是close阶段,server端是监听listen阶段。
然后client会随机一个序列号seq,放入TCP,将其SYN标志位置1,表示发送SYN报文,client处于SYN-SENT(发送阶段)
(2)server收到clientSYN报文,初始化自己的序列号seq=y,填入到TCP头部里,将ACK和SYN置为1,确认号为x+1,将报文发给client,自己处于SYN-RCVD阶段。(接受到阶段)
(3)client端收到server端报文,然后发送应答报文,将TCP头部SYN、ACK置为1,将确认号ack为y+1(服务器端传过来是y),然后seq是x+1,加1。
注意:第三次握手是可以携带数据的,前两次握手是不可以携带数据的
- 为什么握手不是两次?
(1)原因是为了防止旧的重复连接初始化造成混乱。
client发送多个连接请求,可能先发送的比后发送的先到达,于是client端根据上下文判断该序列化过期,或者超时,会发送RST报文,终止。
如果是两次握手连接,就不能判断当前连接是否是历史连接,client第三次报文时,有足够的上下文来判断,根据情况返回。
(2)不能保证同步双方初始序列号
通信时,必须维护好双方的序列号(去重,按序接收,判断是否被接收)。
两次握手只保证了服务器端的初始序列号能被对方成功接收,没办法保证双方的初始序列号都能被确认接收。
(3)会造成重复建立连接,资源浪费
因为TCP有超时重发机制,旧请求不阻塞了,到达了服务器端,则服务器重复接受无用的 SYN 报文,而造成重复分配资源,浪费资源。
- 为什么不是四次?
三次握手就能保证连接建立,四次则优化成三次。
4. 为什么握手是三次,挥手却是四次?
- 挥手目的:
很形象,挥手代表着断开连接。
- 挥手过程:
任何一方都可以主动的断开连接,即需要四次,一方关闭然后另一方同意,然后另一方再发断开,一方再同意。
(1)client打算关闭连接,然后发送了FIN报文,FIN = 1,序列号seq = x,进入FIN_WAIT状态。
(2)服务器端收到client的关闭连接,然后发送ACK应答,ACK = 1,ack = x + 1,seq = y,进入CLOSED_WAIT。client端进入FIN_WAIT2状态。
(3)服务器端处理完数据,然后再向client发送FIN报文,FIN = 1, seq = z,ACK = 1, ack = x + 1,服务器端进入LAST_ACK状态。
(4)client端收到FIN报文,回一个ACK应答,ACK = 1,ack = z + 1,seq = x + 1,进入 TIME_WAIT 状态,然后服务器收到ACK,进入CLOSE状态。
客户端经过2MSL时间,自动进入CLOSE状态。
- 为什么挥手是四次?
经过上面的过程可知,服务器收到客户端的 FIN 报文时,先回一个 ACK 应答报文。应答方(接收挥手的一方)ACK 和 FIN 一般都会分开发送。
而服务端可能还有数据需要处理和发送,等服务端不再发送数据时,才发送 FIN 报文给客户端来表示同意现在关闭连接。
- 为什么 TIME_WAIT 等待的时间是 2MSL?
MSL 是 Maximum Segment Lifetime,报文最大生存时间,它是任何报文在网络上存在的最长时间,超过这个时间报文将被丢弃。
最后一次挥手可能丢失,超时,server端会重新发一次第三次挥手的FIN报文,然后client端再回复ACK。所以一来一回需要等待 2 MSL的时间。
5. 说一下TCP 超时重传与快速重传
- 可靠性保证:
TCP 是通过序列号、确认应答、超时重发、连接管理以及滑动窗口等机制实现可靠性传输的。
- 超时重传
TCP 针对数据包丢失的情况,会用重传机制解决。
发送数据时,设定一个定时器,当超过指定的时间后,没有收到对方的 ACK 确认应答报文,就会重发该数据,也就是我们常说的超时重传。
可能的情况:(1)发送数据丢包;(2)确认应答ACK丢失
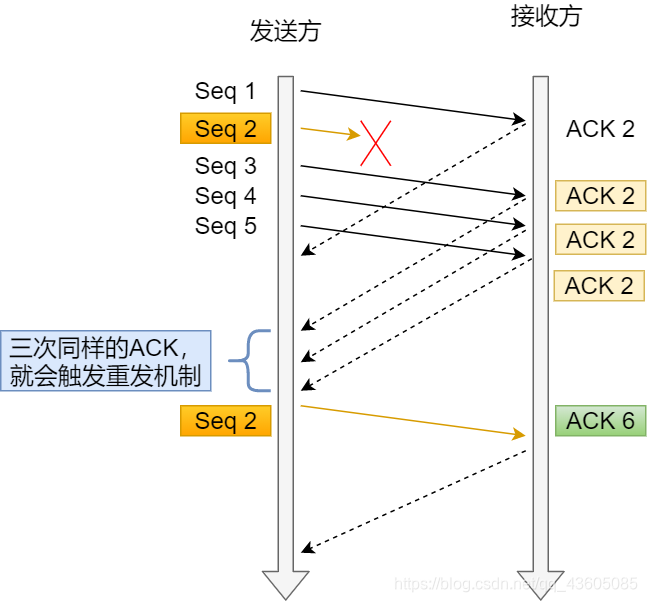
- 快速重传
快速重传就不是以时间来定夺,而是几次接受到同一个ACK,因为有一个请求发送未到达发生丢包,后几次响应返回相同的ACK。
6. 说一说TCP的流量控制以及滑动窗口吧
- 流量控制
发送方不能无脑一直发送数据,因为接收方不一定能够处理的过来,会导致一直超时重发。
TCP 提供一种机制可以让「发送方」根据「接收方」的实际接收能力控制发送的数据量,这就是所谓的流量控制。
发送方每次收到接收方的确认消息,都会根据确认号,挪动窗口的相应位置,使得窗口内出现新的未发送字节,同时接收方还会返回现在滑动窗口的大小来限制发送方的发送速度。
- 滑动窗口
TCP 引入了窗口这个概念,解决数据包的往返时间越长,通信的效率就越低的问题。
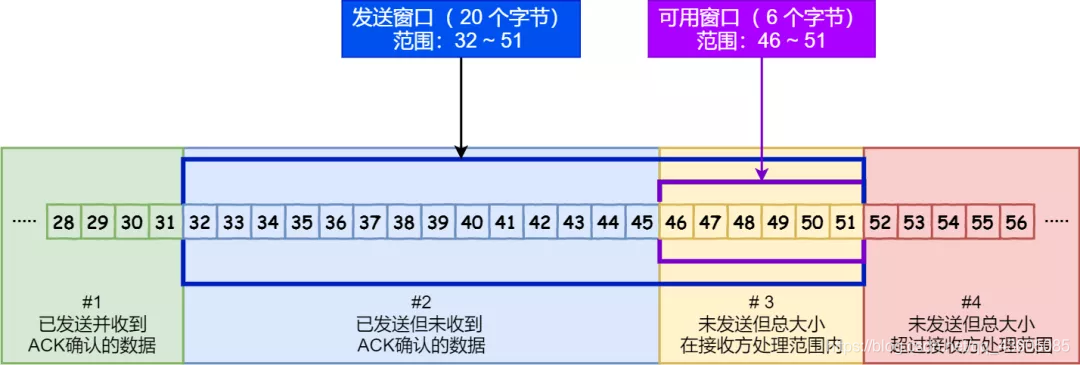
(1)窗口大小:无需等待确认应答,一次性发送数据的最大值,以字节为单位。
窗口实际上是OS开辟的一个缓存空间,发送方<=接收方,并且OS会一直调整。
(2)累积应答:图中的 ACK 600 确认应答报文丢失,也没关系,因为只要发送方收到了 ACK 700 确认应答,就意味着 700 之前的所有数据「接收方」都收到了。这个模式就叫累计确认
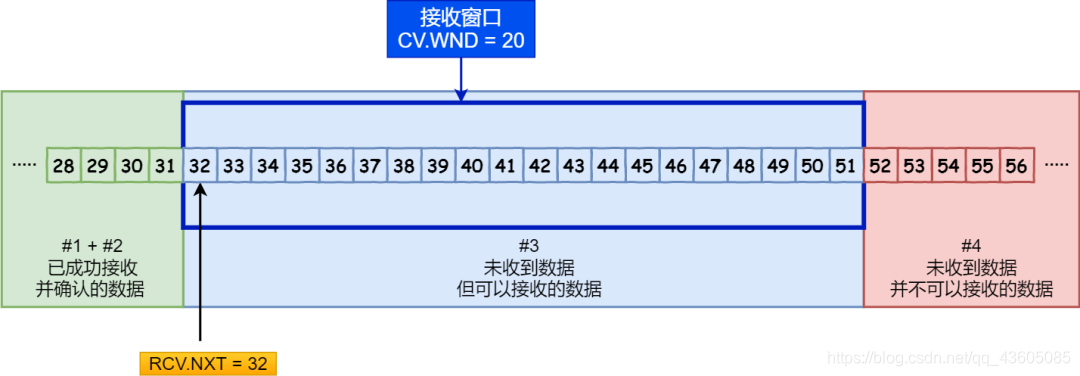
(3)接收方滑动窗口
7. 流量控制有哪些问题?
- 糊涂窗口综合征
因为发送方每次发送的包都很小,接收方刚腾出一点空间,让发送方开个小窗口,由于窗口小就只能发送很少的数据。这样每次发送数据少,且由于数据头部40个字节的固定开销存在,导致发送速度更慢,所以针对某一遍性能差有两种解决思路。
所以解决方式:
(1)避免发送方发送小窗口
强制不发送小数据,囤积数据,满足一定大小条件才发送。
(2)避免接收方不通告小窗口给发送方
这个还是比较好想的,当 窗口大小 < Min(一个报文长度,缓存空间 / 2)时就给发送方通告窗口为0。
8. 为什么TCP设置拥塞控制?不是已经有了流量控制嘛?
目的:避免发送方的数据填满整个网络通信,在发送方调节要发送数据的量。
与流量控制的区别:流量控制是避免发送方的数据填满接收方的缓存(窗口)。
拥塞窗口 cwnd = min(cwnd, rwnd),也就是拥塞窗口和接收窗口中的最小值。
拥塞控制主要是四个算法:
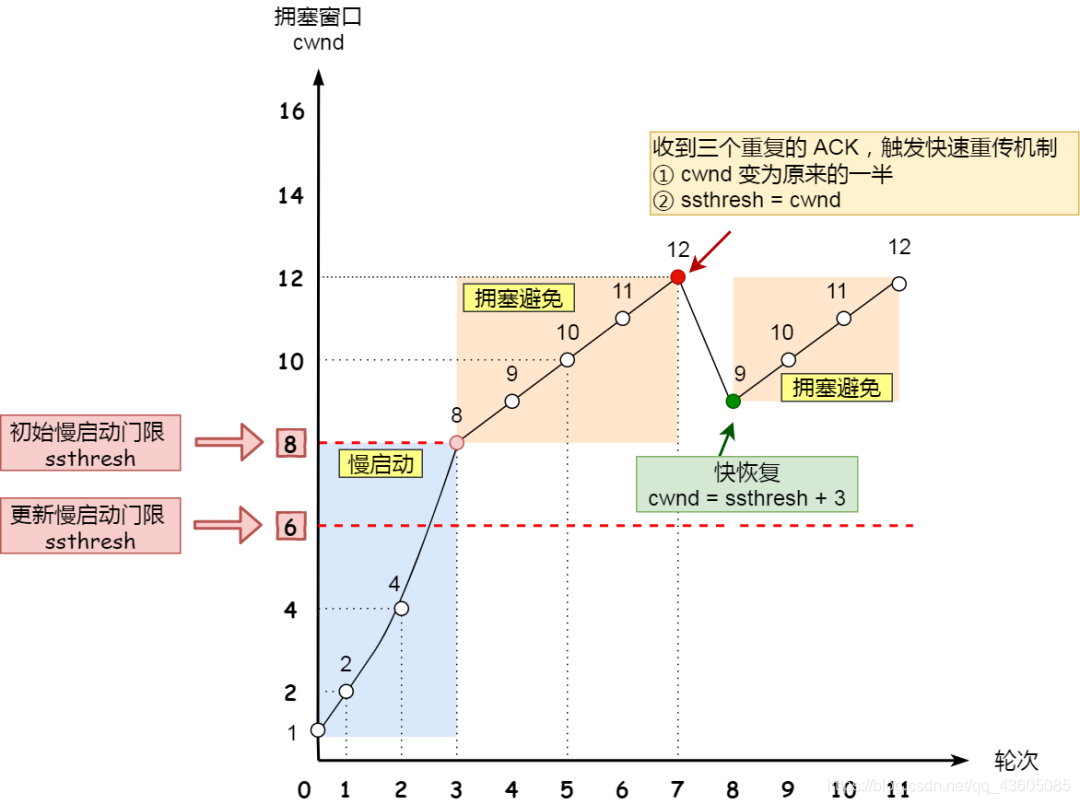
- 慢启动:
一点一点的提高发送数据包的数量,每返回一个ACK,cwnd就增加1,当到达门限时就退出慢启动。
- 拥塞避免:
每当收到一个 ACK 时,cwnd 增加 1/cwnd。
- 拥塞发生:
出现丢包现象,这时就需要对丢失的数据包进行重传。当触发了重传机制,也就进入了「拥塞发生算法」。
- 超时重传:将门限设置为原来1/2,窗口重置为1。(太抖了,不用)
突然减少数据流,然后一般会造成网络卡顿。
- 快速重传
与超时重传区别是,窗口设置为原先的1/2,然后门限也是现在的窗口。
- 快速恢复:
一般跟快速重传一起使用,还能收到3个相同的ACK,不那么糟糕,则窗口设置为门限 + 3,重传丢失的,进入拥塞避免状态。
综合面试题:能说一说键入网址后,期间发生了什么?
总结:
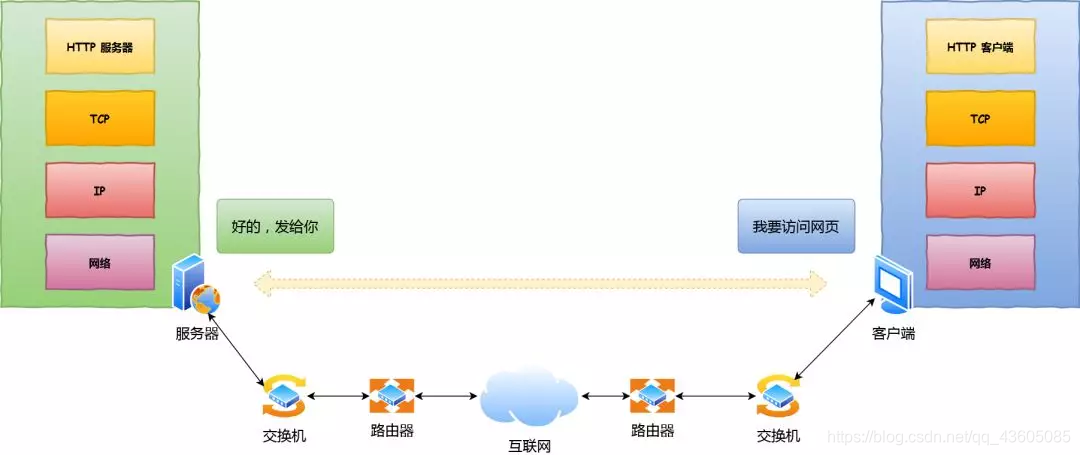
一个数据包的心路历程:
- HTTP
对url进行解析,生成Http请求报文,确定了Web服务器和文件名。
- DNS域名解析:指路不带路
查询服务器域名对应的 IP 地址,顶级DNS服务器(com)。。。
- TCP进行可靠传输
DNS获取到IP后,就可以把Http报文的传输工作交给OS的协议栈。
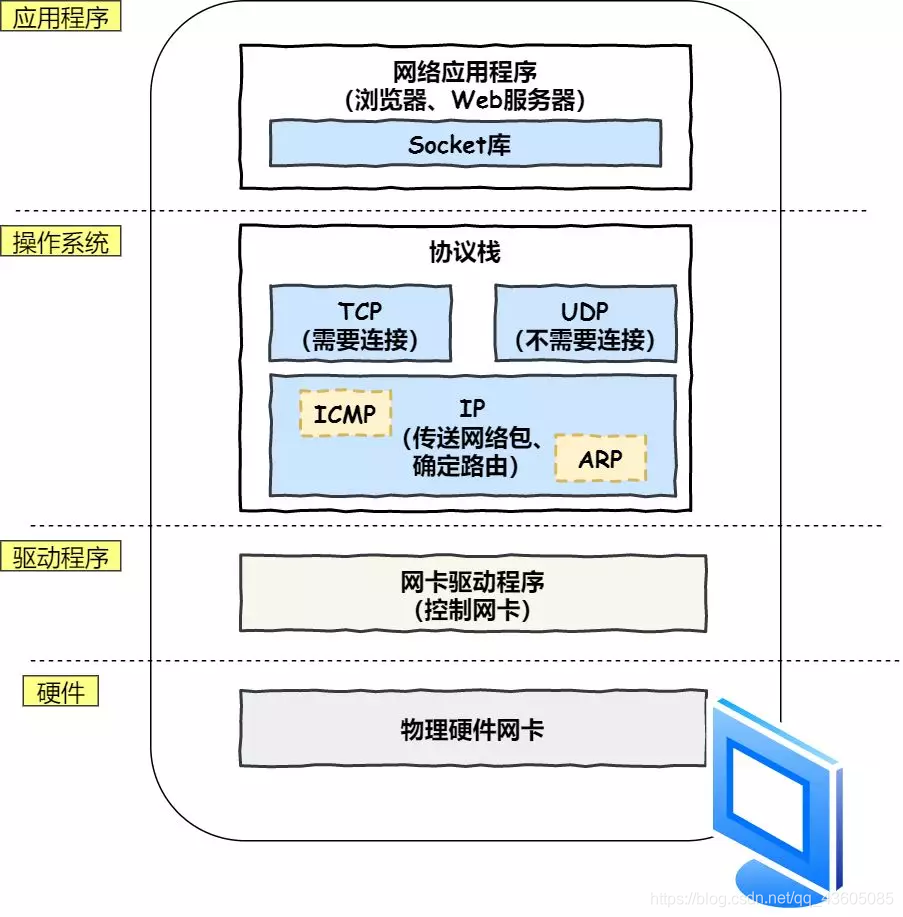
程序通过调用 Socket 库,来委托协议栈工作。HTTP 是基于 TCP 协议传输的,TCP 传输数据之前,要先三次握手建立连接来保证双方都有发送和接收的能力。然后生成报文进行传输。
TCP报文包括先前生成的HTTP报文头 + 数据 进行组装。
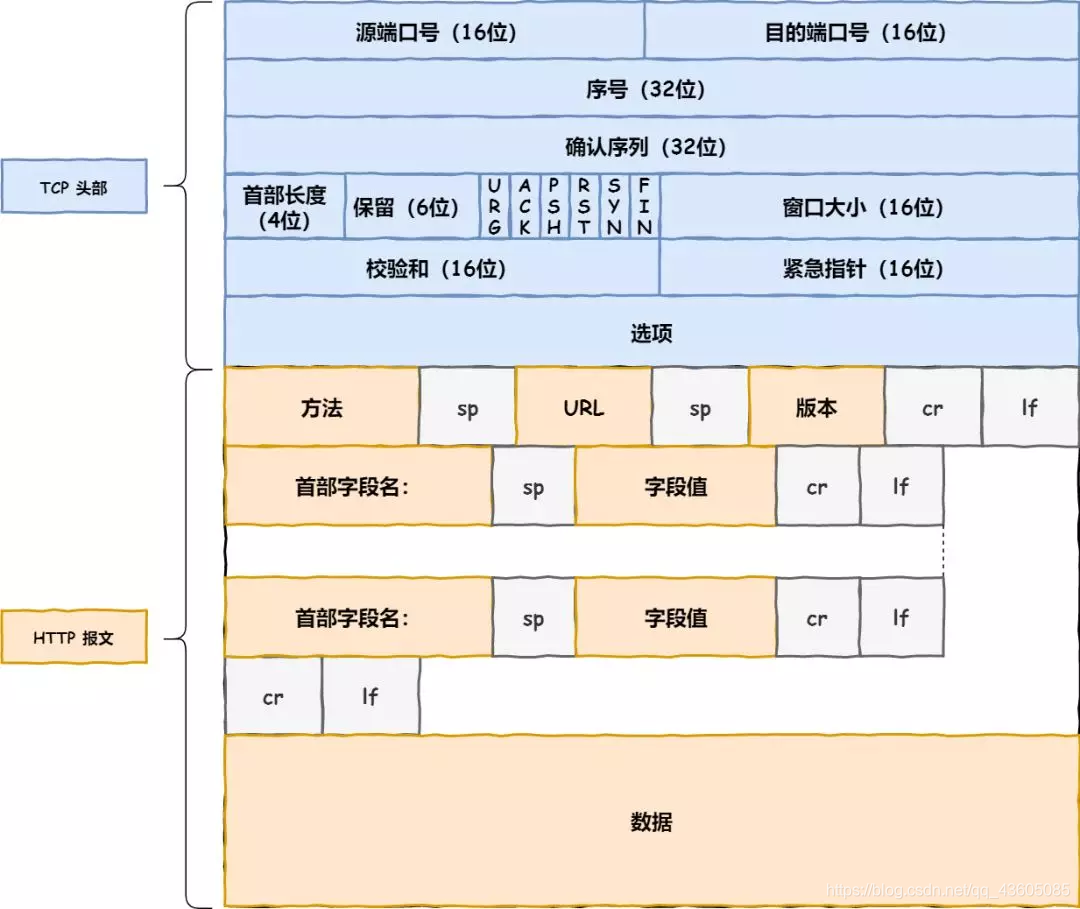
- IP进行远程定位
TCP在执行连接、收发、断开等各阶段操作时,都需要委托 IP 模块将数据封装成网络包发送给通信对象,即加了一层IP头部。
- MAC协议进行两点的传输
需要通过ARP协议帮助我们知道对方的路由器MAC地址。ARP 协议会在以太网中以广播的形式获取到。
- 网卡进行数据的物理传输
网卡驱动从 IP 模块获取到包之后,会将其复制到网卡内的缓存区中,接着会其开头加上报头和起始帧分界符,在末尾加上用于检测错误的帧校验序列。
能在交换机和路由器的转发下,抵达到了目的地。
三、DB(Mysql)
1. 说一说事务的四大特性有哪些?
事务主要是四大特性,ACID
总结:原子性和持久性是通过日志恢复(undo log,redo log)实现;隔离性是通过并发控制(锁)来实现的,而原子性、隔离性、持久性巩固实现一致性。
- 原子性(Atomicity)
- 一致性(Consistency)
- 隔离性(Isolation)
- 持久性(Durability)
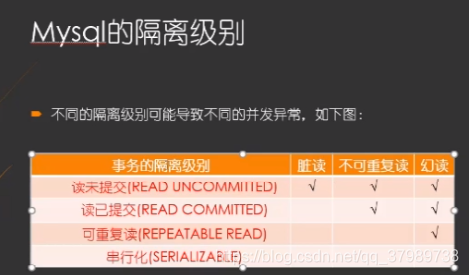
2. 能说一说事务的隔离级别嘛?
因为完全的隔离性会导致并发的性能很低,所以我们一般把事务隔离级别从低到高划分:
读未提交Read uncommitted: 读写锁均在操作完成后立即释放。
读已提交Read committed: 防止脏读。读锁在读完成后立即释放,写锁持续到事务结束释放。Oracle和sql server的默认隔离等级。
可重复读Repeatable read: (Mysql默认)防止脏读、不可重复读。读写锁均持续到事务结束释放。
串行化Serializable: 防止脏读、不可重复读和幻读。不再锁定行,而是锁定表。直接将表操作串行。
3. 说一说Mysql表结构存储引擎种类,以及它们的不同吧
主要是两种引擎,MyIsam和InnoDB:
- MyIsam不支持事务、外键,仅支持表级锁。适合执行大量的select和insert。
- InnoDB支持事务、外键,支持表级锁和行级锁。如果表中既无主键也无索引,将自动创建一个隐藏主键列。适合执行大量的delete和update,适合大尺寸数据库。
不同之处主要就是:
- MyIsam不支持事务,而InnoDB是支持事务的。
- MyIsam是非聚集索引,
索引和数据文件是分离的(非聚集),每个叶子节点存储的都是数据的磁盘指针;InnoDB是聚集索引,表数据文件本身就是按B+Tree组织的一个索引结构文件。 - InnoDB表必须有主键,并且推荐使用整型的自增主键,B+树有序,插入数据方便,并且范围查找高效。
4. Mysql为什么选取B+树作为索引?

- 非叶子节点不存储data,只存储索引(冗余),可以放更多的索引。
- 叶子节点包含所有索引字段,且节点索引依次递增。
- 叶子节点用指针连接,提高区间访问的性能。
5. 说一说数据库的三范式吧
1NF
数据库表的每一列都是不可分割的原子数据项,例如不能出现学生字段,数据为“张三 男 18岁”。
2NF
在1NF的基础上,非主键字段完全依赖于主键。
3NF
在2NF基础上,任何非主属性不依赖于其它非主属性(在2NF基础上消除传递依赖)
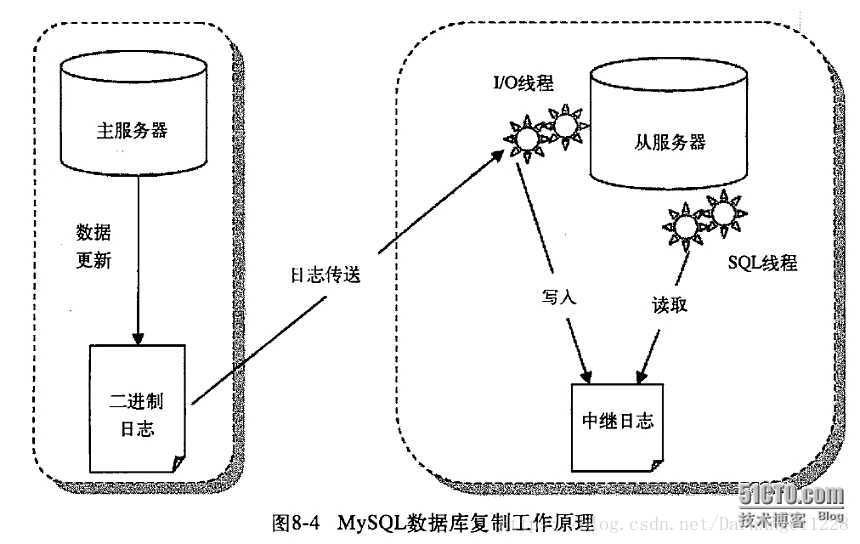
6. 说一说你理解的Mysql主从复制吧
- 作用:
- 数据热备
- 多库存储,读写分离
- 步骤:
- 主数据库操作,sql语句写入数据库的同时,写入binlog二进制文件,主要是一些SQL语句(写库,所以是增删改)。
- 主库通过I/O线程发送binlog,写入至从库replay log
- 从库执行SQL线程将replay log,写入至从库的bin log data中。
7. 能说一说常见的数据库优化方式嘛?
- 若表中很少对数据进行更新,且经常只查询某几个字段,可对这几个字段都创建索引,加快速率
- 通过explain来查看SQL语句的执行效果,可以帮助更好的选择索引和优化查询语句,写出更好的优化语句。
- 避免使用select * ,用具体的字段列表。
- 不在索引列做运算或者使用函数
- 查询尽可能使用
limit减少返回的行数,减少数据传输时间和带宽浪费。
四、缓存(redis)
1. Redis中有哪些数据结构?
Redis是一个键值对非关系型数据库,key一直都是String类型,而value有五种数据类型:
String、List、Hash、Set、Zset

2. 能说一说Redis中缓存淘汰策略嘛?
缓存淘汰主要分为三类:
- 对设置了过期时间的数据valatile
valatile-lru:最近最少使用数据
valatile-ttl:将要过期的数据
valatile-random:随机选取
- 对全局数据
allkeys-lru
allkeys-random
- 直接报错,不淘汰数据
no-enviction(驱逐)
3. Redis的数据过期策略有哪些?
就是检查数据是否过期的策略:
- 定期检查:定时遍历redis删除
- 惰性检查,get时再检查
但我们一般就综合使用,惰性检查 + 定时检查
4. Redis如何实现与数据库一致性?
Redis要与数据库的数据保持一致性,可能在并发修改时会产生不一致。
先删缓存,再更新数据库,可能出现不一致问题,写入缓存时,另一线程进行更新数据库。
所以使用延时双删策略:先删除缓存,更新数据库,延时,再次删除缓存,就能大概率避免。
5. 说一说缓存击穿、缓存穿透、缓存雪崩的区别以及解决办法吧
- 缓存击穿
缓存中的某个热点数据到期后,大量请求击穿,发到DB
解决:
- 最简单就是热点数据设定永不过期
- 不存在的数据加个互斥锁(setnx来实现),避免一瞬间大量请求。
- 缓存穿透
大量请求访问一个不存在的数据,即缓存和数据库中都没有
解决:
- 返回空值给缓存
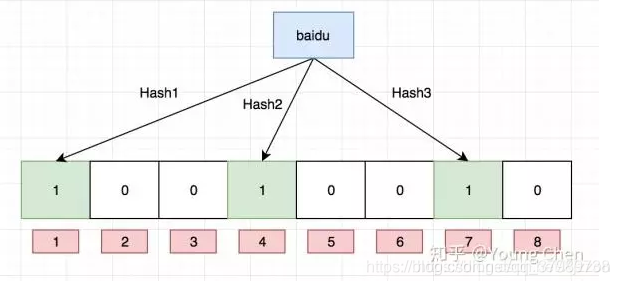
- 使用布隆过滤器,维护一个集合保存所有可能被访问到的key,不存在的key直接过滤掉。
k个同时为1,才代表有,但可能误判
- 缓存雪崩
较短时间内,缓存中大量的热点数据集体过期,造成一瞬间DB的压力骤增
解决:
- 还是避免同时过期,则要使热点数据过期时间分散
- 热点数据分布在分布式的数据库中
- 或者就直接永不过期。
6. 说一说Redis中的持久化
Redis的持久化主要分为两种,一个是RDB快照,一个是AOF日志
RDB快照是数据库的完整备份,里面有全部数据,保存时就将快照保存在dump.rdb文件中,启动时加载。
RDB实现:主要是
fork出一个子进程,然后这个子进程就会处理接下来的所有保存工作,父进程无须执行任何磁盘 I/O 操作。AOF是将修改的每一条指令记录进文件,避免了save才去保存,实时性强。
AOF实现:改变数据集的命令时(比如 SET), 这个命令的反向命令就会被追加到AOF写命令刷新缓存区里,默认每秒一次磁盘操作。重启时, 程序就可以通过重新执行 AOF 文件中的命令来达到重建数据集的目的。
二者的比较:
RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快,但是故障宕机时丢失数据。
AOF 文件的体积通常要大于 RDB 文件的体积,因为有数据的过期,所以恢复慢。
7. 说说Redis中的哨兵模式吧
Redis采用哨兵进程监控主redis服务器和从redis服务器。当主服务器宕机,哨兵通知其他从服务器切换为主机。(哨兵之间也会互相监控)哨兵会向主从服务器发送hello指令,以确保其状态,然后在哨兵之间网络进行消息互通。
领头哨兵在主机故障时进行自动故障转移,并从从服务器间选择一个作为一个新服务器。