Java集合类
1、Java集合容器包含了哪些?
主要就是List、Set、Map接口,以及实现了这些接口的子类。
List、Set是继承自Collection接口、Map是单独的接口
2、List、Set、Map有何区别?
如同他们名字一样:
- List:列表,有序,可以插入相同的值、null
- Set:集合,无序的,元素不能重复,所以就只能存一个null
- Map:是映射,存储的是Entry键值对(1.8之后是Node),key唯一,则只能存一个null的key,value可以存多个值为null
3、ArrayList存储结构和特点
ArrayList顾名思义嘛,是数组列表,底层使用数组实现,当装载的是基本类型时,例如Byte,int,boolean,要使用他们的包装类例如Interger
- 底层是一个Object数组,elementData
- 特点是:查询效率高,但是增删的话(一般使用LinkedList)效率就低,线程也不安全,但是使用频率高
4、ArrayList底层是数组,数组是定长的,那扩容怎么办?
ArrayList可以初始化长度,当空间不足时,则进行扩容。
扩容机制:
- 重新定义一个新数组,大小为原来的1.5倍(size + (size >> 1))
- 然后将原数组copy到新数组,再进行添加操作
5、ArrayList空参构造和初始化大小0的不同?
- 空参构造时,即
new ArrayList(),空间大小为DEFAULTCAPACITY_EMPTY_ELEMENTDATA = 0,然后add时,扩容为10 - 初始化大小为0时,即
new ArrayList(0),空间大小为EMPTY_ELEMENTDATA也是0,但是add时,扩容为1
6、 ArrayList为什么elementData加上transient关键字
因为不想让整个数组空间都序列化,比较耗费资源,ArrayList内部有实现的序列化和反序列化方法
7、ArrayList为什么elementData没有private修饰
因为这样可以简化内部类对elementData的访问。
8、ArrayList与Vector的区别
- 第一个简单,ArrayList是线程不安全的,而Vector是线程安全的,每个方法都加了
synchronized关键字 - 第二个重点,在扩容时,ArrayList扩容为原来的1.5倍,而Vector是扩容为原来的2倍。
9、对Vector的所有操作都是线程安全滴吗?
不一定,虽然内部每个单独的方法都加了互斥锁,但是进行复合操作时,就无法保证其安全性。
拓展:Vector是同步容器,降低了并发的能力,所以就有了Java的并发容器(JUC)来进行高效并发
同步容器:Vector、HashTable、Stack
并发容器:JUC下的集合类,进行复合操作时,尽量使用自身提供的线程安全方法。
Stack不建议使用了,因为继承自Vector容器,栈一般用ArrayDeque来实现。
10、实现普通的队列时,ArrayDeque 与 LinkedList 该如何选择?
普通队列只需要在队头取,在队尾插入。
即使用ArrayDeque(底层是数组)即可,使用LinkedList还需要额外维护双向链表,增大了开销。
11、ArrayDeque 与 LinkedList 区别?
- 一个是数组实现,一个是双向链表实现
- 一个不可存储null值,LinkedList可以存储null值
12、说说Set集合的实现类,以及特点
Set就是我们数学上的集合,无序,不重复。
分类:HashSet、LinkedHashSet、TreeSet
- Hash实现的话,内部维护了一个HashMap,Set的值作为key,值是一个Object类型,key是指向这个对象的。
- LinkedHashSet,内部加了一个LinkedList双向链表来保留插入的顺序
- Tree实现的话,内部是红黑树实现,但查询没有Hash快
HashMap
1、能说说HashMap内部结构是怎么样的?
顾名思义,底层是用了hash表,key由hashcode来计算进行存储,有三种数据结构:数组 + 链表(1.8之后是红黑树,加快了查询效率)
key经过hash函数(取hashcode,然后位运算取模)的运算,得到数组索引,数组table存储的是Entry键值对(1.8之后是Node),里面有key,value,还有hash值,以及链表的next
当发生哈希碰撞时,就会在桶的位置形成链表,采用头插法进行维护链表,1.8之后是尾插法进行维护链表。
2、HashMap中字段例如Node数组table要使用transient
看源码发现,HashMap中的字段,例如:Node数组table,entrySet,size,modCount(结构修改次数)
让这些敏感字段不被序列化成字节信息,从而反序列化成对象时,属性消失。
transient Node<K,V>[] table; |
3、HashMap为什么要设置modCount(fail-fast、fail-safe)?
modCount,指的是对HashMap结构发生修改的次数
java.utils 包下的集合类都是遵循fail-fast,快速失败机制的,多线程操作下当遍历时发现modCount不匹配时,就会迅速抛出异常。
fail-fast:
使用迭代器遍历元素的过程,如果集合的结构被改变的话,就会抛出异常,防止继续遍历。这就是所谓的快速失败机制。
fail-safe:
顾名思义:安全失败,他就不会抛出异常,会在复制原集合的一份数据出来,然后在复制的那份数据遍历。
注意:juc包下的并发容器都是fail-safe,因为它会复制一份进行操作,所以就不保证数据时最新数据。
4、HashMap中的hash值计算时,为什么 (h = key.hashCode()) ^ (h >>> 16)
(h = key.hashCode()) ^ (h >>> 16)
实际上是将hashcode的高16位 与 低16位进行异或操作,这样高低16位信息都用上了,能够让hash值更分散,减少hash碰撞。
5、HashMap的数组容量length为什么是2^n,如果指定初始化不为2^n怎么办?
- 为什么数组容量length是2^n
由插入时源码得知,插入到对应桶位置的时候,是根据 (n - 1) & hash进行位运算取模计算桶的数组下标
因为2 ^ n - 1 转换成二进制就变成全1,&运算等价于取模。
if ((p = tab[i = (n - 1) & hash]) == null) { |
- 指定初始化容量不为2^n,怎么办?
当我们new一个HashMap(int Capacity)时,实际上并不是直接采用这个容量,而是将第一个比它大的2^n,作为容量。
public HashMap(int initialCapacity, float loadFactor) { |
6、在Node节点中,重写equals方法时,为什么建议重写hashcode方法?
因为equals方法中,通过比较key和value是否一样来判断相同的,保证二者是同一个节点。
public final int hashCode() { |
没有重写hashcode方法,会出现equals相等而hashcode不相同的情况,保证同一个链表上的对象返回不同的hashcode值,这样去get的时候,才能拿到具体的链表上的节点。
同时使用hashcode方法提前校验,可以避免每一次比对都调用equals方法,提高效率。
7、HashMap是数量达到容量才扩容?扩容机制
HashMap当元素数量达到阈值threshold,就进行一次扩容,扩容为原来的2倍,然后重新插入。
阈值 threshold = size * LoadFactor(负载因子,默认0.75)
- 新数组容量扩为原来2倍
查看源码resize函数:发现每次扩容都是oldCap << 1,扩容为原来的2倍。
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && |
- 数据重新插入到新数组,以及碰撞后的链表
重新计算Hash值,进行插入到新数组,发生碰撞再插入进链表。
8、为什么HashMap扩容时线程不安全?
Java1.8之前采用头插法
- 数组中位于同一个桶的node,链表中元素会在扩容的插入时前后链表顺序倒置,就会引发线程安全问题。
- 多线程进行插入时,就会陷入死循环,指向混乱或丢失,从而形成环形链表,或者数据丢失
Java1.8之后hash碰撞就采用尾插法
尾插法不会改变前后链表顺序,就不会形成这种情况,但我觉得还是会造成数据覆盖的情况。
因为多线程可能同时进入判断桶中是否有数据,当其中一个挂起时,重新获得时间片时,可能桶中有数据,这样就会覆盖掉原数据。
9、HashMap是线程不安全的,如何处理?
一共有三种方式:
Collections.synchronizedMap(Map)创建线程安全的map集合;
内部有一个Map和一个mutex排斥锁(默认是this),创建线程安全的map时,会对方法进行上锁。
- 使用Hashtable
我看过他的源码,他在对数据操作的时候都会上锁,所以效率比较低下。
- 使用ConcurrentHashMap
不过出于线程并发度的原因,我都会舍弃前两者使用最后的ConcurrentHashMap,他的性能和效率明显高于前两者。
10、能说说HashMap和HashTable的不同?
- 实现方式不同,Hashtable 继承了 Dictionary类,而 HashMap 继承的是 AbstractMap 类。
- 初始化容量不同:HashMap 的初始容量为:16,Hashtable 初始容量为:11,两者的负载因子默认都是:0.75。
- 扩容机制不同:当现有容量大于总容量 * 负载因子时,HashMap 扩容规则为当前容量翻倍,Hashtable 扩容规则为当前容量翻倍 + 1。
- 迭代器不同:HashMap 中的 Iterator 迭代器是 fail-fast 的,而 Hashtable 的 Enumerator 不是 fail-fast 的。
- Hashtable使用的是安全失败机制(fail-safe),不能存入null值:无法判断对应的key是不存在还是为空,因为你无法再调用一次contain(key)来对key是否存在进行判断,ConcurrentHashMap同理。
ConcurrentHashMap
1、说说ConcurrentHashMap的数据结构,以及为啥他并发度这么高?
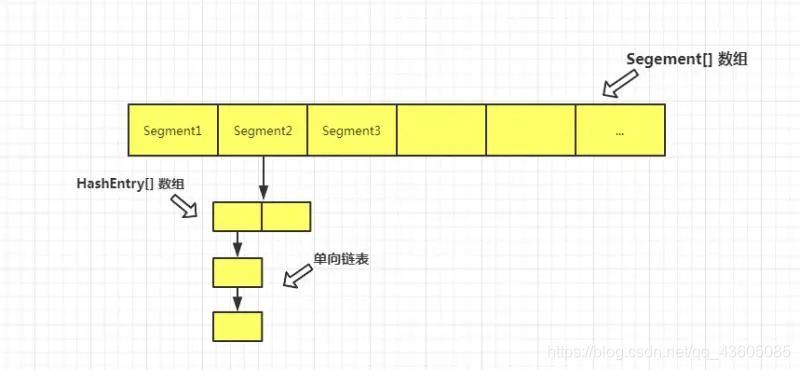
jdk8之前:Segment 分段锁
还是采用
链表+数组的形式存储键值对的,但是为了并发操作,而又避免了将整个数组锁住,就把原来的整个 table 划分为 n 个 Segment ,每个Segment对应一把锁,多个线程访问不同的segment。每个 Segment 里边是由 HashEntry 组成的数组,每个 HashEntry之间又可以形成链表。
static final class Segment<K,V> extends ReentrantLock implements Serializable { |
ConcurrentHashMap 采用了分段锁技术,Segment分段锁继承ReentrantLock,每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment。在并发数高的时候,ReentrantLock比Syncronized总体开销要小一些。
HashEntry使用volatile去修饰了他的数据Value还有下一个节点next。
- jdk8之后:CAS + synchronized
1.8之后抛弃了原有的 Segment 分段锁,而采用了 CAS + synchronized 来保证并发安全性。给数组中的每一个头节点加锁,锁的粒度降低了。并且,用的是 Synchronized 锁。
static class Node<K,V> implements Map.Entry<K,V> { |
- 初始化,使用CAS保证并发安全,懒惰初始化
table[]即Node数组 - put,没链表时为CAS创建链表,有就尾插法

